One of the advantages of working with C++ is the ability of the programmer to overload not only functions, but also operators as well. With operator overloading most operators can be extended to work not only with built-in types like floats and ints but also classes. This gives the programmer the freedom to change how a built-in operator is used on objects of that particular class. For example, we can overload the plus, minus and star operators to perform vector addition, subtraction and scalar multiplication on the components of our Vector3 class. (I will be using this Vector3 class as an example of operator overloading for the remainder of this post. For more on vector math see Vectors Part 1.)
The following code sample is an example of a three dimensional vector class which uses operator overloading for many the the various operators that are available. We will examine the syntax of each of these operators individually.
class Vector3 {
public:
float x;
float y;
float z;
//Constructor method
Vector3(float x, float y, float z) : x(x), y(y), z(z) {}
//unary operations
Vector3 operator- () const { return Vector3(-x, -y, -z); }
//binary operations
Vector3 operator- (const Vector3& rhs) const {
return Vector3(x - rhs.x, y - rhs.y, z - rhs.z);
}
Vector3 operator+ (const Vector3& rhs) const {
return Vector3(x + rhs.x, y + rhs.y, z + rhs.z);
}
Vector3 operator* (const float& rhs) const {
return Vector3(x * rhs, y * rhs, z * rhs);
}
friend Vector3 operator* (const float& lhs, const Vector3& rhs) {
return rhs * lhs;
}
Vector3 operator/ (const float& rhs) const {
return Vector3(x / rhs, y / rhs, z / rhs);
}
bool operator!= (const Vector3& rhs) const {
return (*this - rhs).sqrMagnitude() >= 1.0e-6;
}
bool operator== (const Vector3& rhs) const {
return (*this - rhs).sqrMagnitude() < 1.0e-6;
}
//assignment operation
Vector3& operator= (const Vector3& rhs) {
//Check for self-assignment
if (this == &rhs)
return *this;
x = rhs.x;
y = rhs.y;
z = rhs.z;
return *this;
}
//compound assignment operations
Vector3& operator+= (const Vector3& rhs) {
x += rhs.x;
y += rhs.y;
z += rhs.z;
return *this;
}
Vector3& operator-= (const Vector3& rhs) {
x -= rhs.x;
y -= rhs.y;
z -= rhs.z;
return *this;
}
Vector3& operator*= (const float& rhs) {
x *= rhs;
y *= rhs;
z *= rhs;
return *this;
}
Vector3& operator/= (const float& rhs) {
x /= rhs;
y /= rhs;
z /= rhs;
return *this;
}
//subscript operation
float& operator[] (const int& i) {
if (i < 0 || i > 2) throw std::out_of_range("Out of Vector3 range\n");
return (i == 0) ? x : (i == 1) ? y : z;
}
const float& operator[] (const int& i) const {
if (i < 0 || i > 2) throw std::out_of_range("Out of Vector3 range\n");
return (i == 0) ? x : (i == 1) ? y : z;
}
//typecast operations
operator Vector2() { return Vector2(x, y); }
operator Vector4() { return Vector4(x, y, z, 0.0f); }
...
};
Unary Operators:
First let us take a look at the negate (-) operator. The body of this operator simply returns a new Vector3 object with each of its floating point components negated. But what we are most interested in is its declaration. Like a typical function it has a return type which is Vector3 and a parameter list enclosed by parenthesis. But instead of a function name we follow the return type with the keyword operator and then the symbol for the particular operator that we wish to overload, which in this case is the minus sign.
Vector3 operator- () const { return Vector3(-x, -y, -z); }
Overloaded operators can be defined either as class member functions or as non-member functions. Here we define them as class member functions. This means that we do not have to include one of the objects involved in the operation in the parameter list since we can reference that object through the this operator (we could have just as easily written the x parameter in the body of the function as this->x). The parameter list for our unary operator is empty because we are only operating on the current object. If we were to write this as a non-member function its declaration would look something like this:
Vector3 operator- (const Vector3& a) { return Vector3(-a.x, -a.y, -a.z); }
Note that the const written after the parameter list in the class member function simply ensures that the function cannot make changes to the original object. The same functionality is accomplished by the presence of the const keyword in the parameter list of the non-member function. If you do wish the operator to make changes to the original object then you would simply remove the const in either of these places.
Binary/Comparison Operators:
Next let us observe the binary operations of addition and subtraction.
Vector3 operator- (const Vector3& rhs) const {
return Vector3(x - rhs.x, y - rhs.y, z - rhs.z);
}
Vector3 operator+ (const Vector3& rhs) const {
return Vector3(x + rhs.x, y + rhs.y, z + rhs.z);
}
As you can see their declarations are hardly any different from the unary operator except that they have an additional parameter which we have named rhs to indicate that it is the object that appears on the right-hand side of the operator. Note that the parameter is passed as a constant reference. We already discussed what purpose the const holds in this context, but why pass as reference? Often when we pass an object by reference it is because we want to be able to make changes to the object within the body of the function, but in this case we pass it as constant to prevent that from happening. So why do we do this? The answer is simple. Passing an object by value means that we have to take extra time to make a copy of the object that is passed. Passing by reference allows us to skip that step by simply passing the address of the object, thus making our code more efficient. Comparison operators generally work the same way with the exception that they simply return a boolean value.
Now let us take a look at our multiplication operator.
Vector3 operator* (const float& rhs) const {
return Vector3(x * rhs, y * rhs, z * rhs);
}
friend Vector3 operator* (const float& lhs, const Vector3& rhs) {
return rhs * lhs;
}
The first thing we notice is that we actually have two multiplication operator functions. The first one looks just like our addition/subtraction operator declarations except that the parameter is of type float. The second one on the other hand is actually a non-member function that we declare to be a friend of the Vector3 class to ensure that it has access to the Vector3 class’ private methods and variables. Although this class does not have any private methods or variables we still need to declare this function as a friend because otherwise the compiler expects the function to have only one parameter. But why do we need both of these functions in the first place? Strictly speaking, we don’t need both unless we wish to ensure that scalar multiplication is a commutative property of our Vector3 class. Our first function does a scalar multiplication operation for the case where we have a Vector3 object on the left and a scalar (float) on the right of our operator but would not work if we were to reverse the order. That is why we need the second function to perform the operation when the order is reversed. Note that we did not need to do the same thing for the addition operator despite it also being commutative because both the left and the right hand sides are of type Vector3.
Assignment Operators:
Next we will see how we can override the assignment operator.
Vector3& operator= (const Vector3& rhs) {
//Check for self-assignment
if (this == &rhs)
return *this;
x = rhs.x;
y = rhs.y;
z = rhs.z;
return *this;
}
Most of the time we do not really need to override the assignment operator because the compiler generated constructor and assignment operator are usually sufficient. But if our class contains pointers the default assignment operator can sometimes lead to problems because we end up with objects that have pointers to the same location. To avoid these problems you will want to know how to override the assignment operator so that it makes a deep copy as well as how to make a copy constructor. I will not be covering how to do either of these things in this post. The example that I give here has no practical purpose since the default assignment operator does exactly the same thing. However, there are two things worth mentioning if you ever do decide to overload the assignment operator. The first is that, if you want your class to support chain assignment (see example below), the function should return the address of the current object. The second is that you should always check for self-assignment before altering any data otherwise your class may end up releasing the resources that it is trying to copy from.
Compound assignment operators are generally simpler to understand. They combine normal binary operations with an assignment operator.
Vector3& operator+= (const Vector3& rhs) {
x += rhs.x;
y += rhs.y;
z += rhs.z;
return *this;
}
Unlike normal binary operators they are generally meant to make changes to the original object, but like the assignment operator they usually return the address of the object. This allows the programmer to write statements like the following:
a = b += c -= d *= e; //example of chain assignment
Subscript/Function Call Operators:
Next we have the subscript operator.
float& operator[] (const int& i) {
if (i < 0 || i > 2) throw std::out_of_range("Out of Vector3 range\n");
return (i == 0) ? x : (i == 1) ? y : z;
}
const float& operator[] (const int& i) const {
if (i < 0 || i > 2) throw std::out_of_range("Out of Vector3 range\n");
return (i == 0) ? x : (i == 1) ? y : z;
}
Here I define it so that the subscript operator returns one of the vector components based on the integer value passed. Notice however that once again we have two functions. The first behaves just as we would expect. The second one on the other hand is written as a constant function that returns a constant reference. Here the const at the end of the second member function allows the function to be called even on an object that is defined as constant. Without this function the programmer would not be able to access the contents of a constant object using the subscript notation. The reason we return a constant reference is to ensure that the caller cannot modify the contents of our constant vector object.
If we were overloading the function call operator we would similarly wish to define two functions, one for constant objects and one for non-constant objects. We do not override the function call operator in the Vector3 class, but something to keep in mind is that, unlike other operators, the function call operator can have as many parameters as the programmer likes. An example where this might be useful is in a matrix class where the programmer wishes to look up a matrix element by its row and column. You cannot do this with the subscript operator because it only takes one parameter, but it can be done in the following way:
class Matrix4x4 {
private:
float data[16];
public:
float& operator() (const int& row, const int& col) {
return data[row + (col * 4)];
}
const float& operator() (const int& row, const int& col) const {
return data[row + (col * 4)];
}
...
};
Typecast Operators:
Operator overloading can even be used to define typecasting operations for our user-defined classes. Suppose elsewhere we have defined a two-dimensional and a four-dimensional vector class and we want our compiler to know how to cast our Vector3 object into one of these types. We can accomplish this in the following way:
operator Vector2() { return Vector2(x, y); }
operator Vector4() { return Vector4(x, y, z, 0.0f); }
Here we simply write the operator keyword followed by the type we want to cast our object into followed by open and close parentheses. We do not need to define a return type since C++ assumes that we will return the correct type. With the help of these functions we should be able write lines of code like the following without our compiler spitting out an error:
Vector2 v2 = Vector2(1.0f, 2.0f); Vector3 v3 = Vector3(3.0f, 4.0f, 5.0f); Vector4 v4 = Vector4(6.0f, 7.0f, 8.0f, 9.0f); v2 = v3; //compiler implicitly typecasts to Vector2 v4 = v3; //compiler implicitly typecasts to Vector3
End of Lesson:
Well that is it for my lesson on operator overloading. I hope the things you have learned here will be of use to you in designing your C++ applications. If you are interested in reading some more of my postings, you may follow the links below:
 and
and  we can visualize the first vector
we can visualize the first vector  and
and  where
where  and its magnitude is called the scalar projection of
and its magnitude is called the scalar projection of  . Similarly
. Similarly 
 we can easily calculate
we can easily calculate  where
where  is the angle between
is the angle between 


 that we are reflecting and the normal
that we are reflecting and the normal  of the surface that our vector is reflecting off. For simplicity we will assume that the normal vector is normalized.
of the surface that our vector is reflecting off. For simplicity we will assume that the normal vector is normalized.
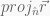 is the same as
is the same as  . Similarly, the projection of
. Similarly, the projection of  onto the plane whose normal is
onto the plane whose normal is  from
from 
 is quite simply a set, whose elements are vectors, for which we have defined two operations: vector addition and scalar multiplication. One example of
is quite simply a set, whose elements are vectors, for which we have defined two operations: vector addition and scalar multiplication. One example of  . For the following operation we will be looking specifically at
. For the following operation we will be looking specifically at  . A basis of a vector space is a subset of vectors
. A basis of a vector space is a subset of vectors  in
in  for any scalar constant
for any scalar constant 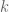 when
when  . We say that a basis spans a vector space so long as any vector
. We say that a basis spans a vector space so long as any vector 
 . An orthonormal basis is simply a basis whose vectors are normalized and whose inner product is
. An orthonormal basis is simply a basis whose vectors are normalized and whose inner product is  when
when 
 are an orthonormal basis representing the x, y and z coordinates of Cartesian space.
are an orthonormal basis representing the x, y and z coordinates of Cartesian space. . The only difference is that instead of scalar values we are using vectors for
. The only difference is that instead of scalar values we are using vectors for  and
and 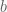 . Like with scalar values it is often a good idea to clamp our
. Like with scalar values it is often a good idea to clamp our  value to somewhere between
value to somewhere between  and
and 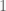 so as to never overshoot the endpoints. A code sample might look like this:
so as to never overshoot the endpoints. A code sample might look like this:


 and
and 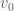 are the initial position and velocity,
are the initial position and velocity, 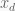 is our target position,
is our target position,  is the frequency of the spring which can be represented as 2 divided by the smooth time. To understand how we get these formulas you can read my posting on
is the frequency of the spring which can be represented as 2 divided by the smooth time. To understand how we get these formulas you can read my posting on  is the displacement vector,
is the displacement vector, 
 , and distributive, meaning that:
, and distributive, meaning that: and
and 

 . We see
. We see 
 and
and  . Vector addition is both commutative and associative. Associative means that:
. Vector addition is both commutative and associative. Associative means that: .
. and
and  and we want to find the displacement vector
and we want to find the displacement vector  from a point
from a point 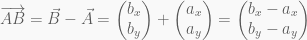

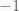 ) and taking the sum of
) and taking the sum of  and
and  to represent the magnitude or length of a vector
to represent the magnitude or length of a vector  and
and  . So by the Pythagorean Theorem:
. So by the Pythagorean Theorem:

 to denote a normalized vector. So the formula for a normalized vector is simply:
to denote a normalized vector. So the formula for a normalized vector is simply:





 and
and  are related in the following way:
are related in the following way: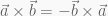
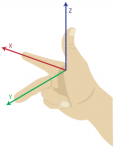
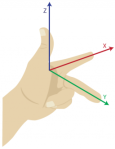
 (right-handed)
(right-handed) (left-handed)
(left-handed)